TOC
Architecture Under Uncertainty Is Hard
Uncertainty is pretty much a given in software engineering (especially at startups). We almost never know as much as we’d like to about our market, our users, or our competitors, and finding product/market fit is inherently a process of educated guessing. And even if you do know a lot upfront, user needs and tastes, competitors, funding landscapes, and technology itself are constantly evolving.
Well, that makes architecture awfully hard. You don’t want to invest a whole bunch of time building something you’re just going to have to throw away or migrate off of, especially if that migration process is itself painful or risky (database migration anyone?). Even worse, you don’t want to build yourself into a hole where you can’t afford to switch gears, and instead are stuck with an architecture or infrastructure that acts as a constant risk or velocity drag.
So what do you do? Just give up? Well, actually sometimes that’s not a bad idea. Sometimes you can push back on building anything at all. Maybe it really is too early to be tackling a new domain where you have no expertise, or maybe you really do need to put the brakes on while you do more upfront diligence (on the product/user side or tech side). But uncertainty isn’t binary. If you were to wait to build anything until you had complete certainty around every possible requirement, you wouldn’t build anything at all.
So let’s assume you have to march forward. Well, at that point a common premise is “just hack everything together as cheaply as possible, because then you don’t care when you inevitably have to throw it away”. Honestly, this is actually reasonably sound advice in a lot of cases (and that’s coming from a platform/infra guy ;). But it’s not always the right answer. You have to consider the fact that by choosing to hack upfront, you are definitely going to need a total rewrite sooner rather than later, and that you are going to have to live with the friction of working on top of a hackjob in the meantime (which sometimes ends up being a lot longer than you think when everyone backs down from the “total rewrite” they committed to upfront).
But the spectrum from “hack it together” to “high quality” isn’t binary either. There can be a have-some-of-your-cake-and-eat-it-too compromise where just a little more upfront diligence and thought into your architecture lets you get the benefit of higher quality systems, while de-risking uncertainty and future change.
I call this architectural tenet “future welcome” (in contrast to any sort of notion of future proof anything). The goal is to design your systems in such a way that they can be adapted or respond to change with as little rework or risk as possible, because we know change is inevitable. So let’s jump in!
Step 1: Are You Sure It’s The Right Time?
It’s important to be brutally honest with yourself as you consider any highly uncertain projects. Do you actually need this project right now? And if so, should you be investing in building it future welcome, or should you just hack something together for now?
As an example, a few years ago I got roped into a data infrastructure project by a high-level product leader who said it was extremely important strategically. It was a legitimately compelling vision (and the tech problem was super fun), so I jumped in. But then we realized that our client teams had literally no compelling use cases for us (read: MASSIVE uncertainty). Somehow we decided that the right path forward was to try and brainstorm what all their possible use cases might be and then solve for every single one of them (read: MASSIVE stupidity)1. After six months of building, we tried to launch our sweet new infra, and only got a single client to adopt in the first 6-12 months. Now, eventually, people did start coming around, but only much later, at which point we had way more clarity on what they needed and could have drastically simplified what we built.
Step 2: Assess the Uncertainty Landscape
OK. So yes, you’ve looked deep into your heart (and probably some spreadsheets) and decided that taking on an uncertain project and investing in a future welcome architecture is the right thing. Your next step is to take a detailed look across the project and survey the shape of the uncertainty. In particular, you’re looking for:
- Areas of “high uncertainty”. Where do you know the least about requirements, or where do you think requirments are most likely to change? This could be due to a lack of product/market fit, lack of user understanding, lack of domain knowledge or technical experience, dependence on third-parties subject to change, etc. If it helps, you can always ask yourself the inverse - where you are confident of what your doing (“regardless of where we end up, we’ll need something like foo that has properties x, y, and z”).
- Areas where change is costly. Where would making changes cause massive risk or rework? For example, migrating to an entirely new database or having to renegotiate an entire business deal.
- Areas of “known expansion”. Are there any areas where you know a lot of change is coming, and while you don’t know the details, you do sort of understand the shape of the change? For example, you don’t know exactly what analytics events you’ll need, but you do know you’re going to need a lot of them over time, and they’ll generally have similar shapes.
- Development boundaries. Who will develop on which parts of the system?
- Ownership boundaries. Who will own (be responsible and accountable for) which parts of the system (and this may not line up with development - e.g. you could have one team that owns a framework, but many teams that add components)?
Step 3: Design Principles
Alright, so let’s build something! None of these principles are brand new (and most are relevant to some extend during any design process), but they are definitely worth reemphasizing and prioritizing when you’re dealing with a lot of uncertainty.
A Little More Decoupling
It’s (hopefully) standard practice to decouple your systems in order to achieve system properties like consistent or simple abstraction, independent scaling, resource and fault isolation, or tech stack specialization. Introducing just a little more decoupling along a couple of axes can have a huge impact on your ability to adapt to future change.
- Decouple Areas of High Uncertainty. The idea is to encapsulate the areas of high uncertainty in order to insulate the rest of the system from them. Don’t understand some piece of the puzzle? Wrap it in a clean interface (or any interface) so that you can change it willy-nilly later without perturbing everything else. And the harder the boundary the better (e.g. API better than module better than class).
- Decouple By Development Boundaries. When change does inevitably drop, you want it to have the lowest blast radius possible in terms of the number of humans impacted. If you separate out systems by which teams or bodies of developers generally work on them, then it’s more likely that only one such group (or a minimal number of groups) will be impacted by the change.
- Decouple By Ownership Boundaries. Similarly, when change hits, you want to have to align the least number of people to agree on what to do about it. Separating out systems by ownership minimizes the number relevant stakeholders for responding to the change.
- But Don’t Cut It Into A Million Pieces. It’d be easy to drink the kool-aid here and just break your systems into a million different pieces in the name of “future welcome”, but its important to remember that there is a fine line between system decoupling and system fragmentation. Breaking a system into pieces does incur a complexity cost of its own (especially if the splits aren’t thoughtful), plus the more you break your system apart, the more individual pieces you’ll need to update (and potentially in a thoughtful, coordinated way) whenever change does span them2. So there is an inherent tension and judgment call here.
A Little More Investment
Similarly, just a little more upfront investment can pay substantial dividends.
- Investigate Or Avoid Areas Of Uncertainty With High Cost Change. If you have any capacity for more upfront diligence, focus it here. See if you can either get more certainty upfront or avoid working on the area entirely.
- Build Rigging For Areas Of Known Expansion. If you know there is a lot of change coming with the same general shape, then consider investing in (light) rigging that makes that change as minimal and low-risk as possible. The idea is to minimally perturb the system each time. If when a PM comes to you with “I have a new rule (or event or product card or whatever)", your answer is “oh yeah, just give 20 minutes to add the config (or a subclass or whatever)", then you’ve nailed it.
- Keep It Flexible. That said, you don’t want to over-optimize the system such that it becomes inflexible when your solution needs to change.
But Don’t Over-Invest
So, this is (obviously) always relevant, but it’s especially important in the case of high uncertainty, because the risk of change or rework is so high.
- Simplicity. Simplicity is generally my #1 architectural priority. Complicated things break, are hard to reason about, are hard to debug, and are easy to think you understand when you don’t (especially if you are new to them). If a system feels complicated, it’s complicated. If a system is hard to explain, it’s complicated. If a system breaks a lot, it’s probably complicated. Don’t settle for complicated systems. Keep iterating on your architecture until it feels simple.
- Avoid Hard Stuff For As Long As Possible. There comes a point where you know you need to do something hard (hopefully in 3-12 months ;). Until that point? Don’t do it. In particular, there are a set of patterns that engineers always seem to jump to at the drop of a hat that are extremely defect-prone like caching or manually managing multi-processing primitives rather than using a framework. Don’t do it.
- Innovation is Great, But… Most things have been done before. Really well. This lesson is an incredibly hard one to follow (like really, really hard), but the first thing you should do when thinking about building a complicated system is to learn from how others have built similar systems (or solved similar problems) in the past. And then 80% of the time you should just use one of those solutions.
And Definitely Over-Communicate
The final piece of the future welcome puzzle is to be very, VERY loud with your stakeholders. Make sure they understand the level of uncertainty you’re dealing with, the risk that incurs, why you think it’s worth proceeding anyways, the steps you’re taking to mitigate that risk, and the development ramifications of those mitigations. The last thing you want is for anyone to be surprised 3 months down the road.
Case Study: Model Service
Now for the fun part! A case study to ground all the hand-waving!
An important preface before we start, though. This case study is an artificial synthesis of a set of related problems I have had to solve a handful of different times for different companies. As such, it isn’t an exact replica of any given one. Also, I’m not going to provide either business context or holistic, detailed architectural diagrams out of a very conservative respect for those various companies’ intellectual property. I realize that’ll make things a little less concrete, but my hope is that it’s still better than no case study at all.
The Inputs
The problem we’re trying to solve is to provide an “online dynamic model service”. Here’s what we do know:
- Requirements
- We need to be able to ask the service a fairly small set of predetermined questions.
- The service answers with one of a fairly small set of predetermined answers.
- Deciding on an answer is essentially executing a “model” (in a pure sense, not any particular ML technique).
- Strategy
- We want to take advantage of third-party vendors that already provide similar solutions.
- We want to take advantage of ML techniques to generate answers. We’re interested in both first-party and third-party solutions.
- We want to take advantage of analyst-derived rules in order to both generate answers and “post-process” any third-party or ML-derived output.
- Both ML and rule-based solutions could depend on a wide variety of user, product, or other data from various existing sources.
- Org
- The service will be integrated into many existing client systems.
- There are four distinct conceptual groups of people. Depending on size of company, they may be spread across various parts of the org:
- the engineers building and running the service
- the engineers who own the various client systems that integrate it
- the analysts who derive rules and help vette and configure third-party vendors
- the ML folks who will eventually build first-party ML solutions
- Timeline
- This has to ship VERY SOON.
Here’s what we don’t know:
- The entire set of questions we need to be able to ask.
- The third-party ML vendors we want to use.
- The configuration of our third- or first-party ML solutions.
- The set of rules we want to define.
- The set of data sources we will therefore need.
- The entire set of systems we’ll need to integrate with.
- Whether the service will ultimately provide its intended value (though we have strong belief).
- Whether the product use cases this service is required for will be successful.
The Analysis
So let’s assess the landscape:
- Areas of “high uncertainty”: Data sources, third-party vendors, ML models, and rules.
- Areas where change is costly: Client integrations, any data store selection and schema.
- Areas of “known expansion”: Data sources and rules. To a lesser extent, third-party vendors and ML models.
- Ownership boundaries and Development boundaries: See “Org” above.
The Decisions
As with most architecture problems, we can decompose things into a handful of critical decisions or pivot points.
What’s our client interface?
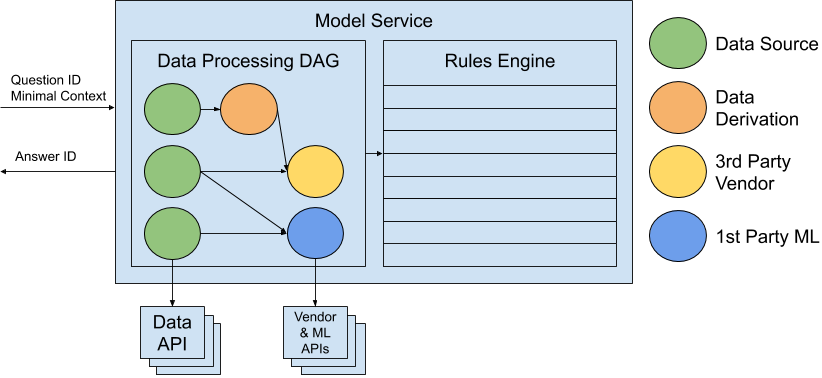
Our client has to pass in a question ID and our service has to return an answer ID, but what about all the input data the service requires? Does the client collect the data and pass it in, or does the service collects everything it needs itself?
The model service API will consist solely of the question ID and any minimal context that doesn’t exist in other sources (e.g. HTTP headers). All other data (user attributes, site activity, market data, etc) will be collected by the service itself. (Decouple Uncertainty, Decouple Dev/Org Boundaries).
- + We can vary data sources, data derivations/transformations, vendors, ML models, and rules without any impact on client systems.
- + Client/service development and organization boundaries are separated by APIs.
- + We incur minimal incremental complexity in existing clients systems for what is still ultimately a speculative project.
- +/- Data handling complexity is centralized rather than pushed out to clients.
What’s our data source?
Should data be pulled live from source of truth APIs, or should data be cached or replicated for local consumption?
The model service will not replicate or cache any of its own data. All data will be pulled on-demand in parallel from sources of truth. (Avoid Uncertainty With High Cost Change, Avoid Hard Stuff).
- + We don’t have to commit to a data store choice, build any data replication machinery, or deal with any data consistency complexity at this time.
- +/- The model service requires a broader set of data access permissions across question use cases (rather than each client for a single use case), but elevated privileges are restricted to a single system that can have heightened security scrutiny and controls.
- (-) Latency is impacted, but after some quick investigation, we confirm that any given system of record will not prohibitively bottleneck E2E performance.
Do we impose any sequencing constraints on data sources, derivations, vendors, ML models, or rules?
There is an entire spectrum from “totally arbitrary” to “strict pipeline of data source => data derivation/transformation => vendor => model => rules”. Where do we want to fall?
The model service will be divided into two stages: “data processing” and “rules engine”. Data sources, derivations, vendors, and ML models will all be modeled generically as data processors that augment a shared data context (i.e. a vendor or ML model’s output is modeled as derived data rather than any kind of final decision). (Keep It Flexible).
- + We can arbitrarily resequence data processors without any impact on the framework.
- + We are able to make decisions holistically based on all data processor output rather than being tied to a particular processor’s decision strategy (an “expert system”).
- + We are able to take advantage of the industry-standard “rules engine” construct.
Do we introduce an abstraction layer for data processors?
Should we introduce an abstraction layer and standard interface for data processors, or just use “inline code”?
The model service will encapsulate data processors behind a standard interface and mini-framework that handles common tasks like logging, metrics, timeouts, retries, etc. (Decouple Uncertainty, Build Known Rigging).
- + We can vary data processor implementations without impacting the rest of the model service. This is particularly important for places where we may want to introduce caching or data replication over time.
- + We can cheaply add new data processor nodes without having to think through standard production bits like logging, metrics, timeouts, retries, etc.
- - We have to invest in some light framework code.
Do data processors execute within the model service or via separate services?
Should data processor implementations execute within the model service or within separate services that the model service calls?
The model service will primarily run data derivations in-service and primarily delegate third-party vendors and ML models to separate services. (Decouple Dev/Org Boundaries).
- + Service/ML model development and organization boundaries are separated by APIs.
- + We are able to maximize concurrency and parallelism for vendors and ML model runs.
- + We maintain simplicity for latency-trivial data derivation.
- - We incur some distributed system complexity cost for vendors and ML model runs.
How do we orchestrate data processors?
Given data processors often have shared, fan-in, or fan-out dependencies, how do we want to orchestrate them to maximize concurrency and minimize duplicated work?
The model service will define the data processing stage for each question as a DAG of data processor nodes. The DAG will be implicitly executed asynchronously and concurrently, such that all nodes not blocking on previous node output are executed simultaneously. (Build Known Rigging).
- + We can add or reorder data sources, derivations, vendors, or ML models without having to think through concurrency or de-duplication details.
- + Latency is lower bounded to actual requirements for serialized processing.
- - We have to invest in some moderately involved framework code. In particular, setting up the async/concurrency framework needs to be done right and is error prone.
Do we build or buy a rules engine?
For the final rules processing stage of our model service, do we want to “buy” an existing rules engine product or package (many exist), or build our own?
We will build our own. The engine will define rules as classes that implement a common interface, and are processed as part of a generic mini-framework that handles common tasks like logging and metrics. (Avoid Uncertainty + High Cost Change, Keep It Flexible, Build Known Rigging).
- + We don’t have to commit to a 3rd-party engine or vendor choice at this time.
- + We have complete flexibility (raw code) to handle any possible rule requirements.
- - We have to invest in some light framework code.
- - Dedicated rules engines are often heavily performance optimized. Ours will not be.
- - We don’t get non-programming analyst/admin UIs for free. Analysts will have to write code or spec rules for engineers.
- + A 3rd-party rules engine could be trivially introduced in the future by modeling it as a terminal data processor node that produces “answer” output, and using a “pass-thru” ruleset.
The Output
So how did it work out? Well, this isn’t a clean answer, because the case study is a synthesis of a set of related problems I’ve worked on, but generally, it’s gone quite well. Development time on the service and framework code has generally been on the order of 2-3 person-months, and is able to handle a large number of use cases with fairly minimal extension or rework. I know all of the examples ran for at least 1-2 years, and as far as I know may have run longer and/or still be running today :)
Moving Forward
I hope that reading this post leaves you feeling excited to build stuff. I now view architecture in high uncertainty contexts as one of my favorite puzzles to solve. It’s hard and it’s fun. You have to figure out when, where, and how to invest; you have to balance getting more certainty versus designing around the lack of it; you have to reflect on the future and what it might bring in terms of product, technology, and organization; you have to communicate the hell out of all these decisions; and usually you have to hustle. Like any Two Ways to Learn post, this isn’t anywhere close to an exhaustive treatment, but I hope it illuminated some useful principles that you can incorporate into your work and gets you thinking about other principles you can derive for yourself!
-
I would describe what we did as an extreme form of “push-based” platform work, where we had strategic faith in a direction or solution, and tried to push adoption onto our clients via some mix of pitching, evangelization, and top-down mandate (or eventually giving up, waiting until they (hopefully) realize they need it, and saying “Ahah! We knew it!” :). This is in contrast to “pull-based” platform work, where we are are building towards a direction or solution that clients are actively requesting. My belief is that high-performing platform teams are like 70-90% pull-based, but occasionally take big push-based bets that can move an organization forward. ↩︎
-
I feel the same way about taking de-coupling too far in the name of isolation. Yes, if you split your monolith into 200 microservices, they’ll all have great resource isolation, but there is a massive complexity cost to distributed systems (that’s another whole blog post at some point). Could you have found a better isolation/complexity tradeoff with 5-10 not-so-micro services instead? And for that matter, you need to be really thoughtful when splitting a system up, regardless of how many pieces. Taking something large and complicated and breaking it up arbitrarily isn’t improving anything, it’s just more dangerous because you think you simplified it. ↩︎
New to Two Ways to Learn? Welcome! Check out the manifesto, enjoy some more posts, and share them if you like! As always, I love questions, feedback, discussion, and requests for follow-up details or examples. Leave a comment, tweet at me, or send me an email!
